
 24th August 2020, 22:06
24th August 2020, 22:06
| #31 |
| BHPian Join Date: Feb 2019 Location: Thane/Kolkata
Posts: 187
Thanked: 508 Times
| |

|  (7)
Thanks (7)
Thanks
|

| |
|
24th August 2020, 22:24
| #32 |
| Senior - BHPian Join Date: Mar 2020 Location: Blr/Kochi/Wynd
Posts: 1,486
Thanked: 7,456 Times
| |
|
|

|
25th August 2020, 01:32
| #33 |
| BHPian | |

| (1)
Thanks
|

|
25th August 2020, 03:00
| #34 |
| BHPian | |
|
| (6)
Thanks
|
|
25th August 2020, 08:31
| #35 |
| Senior - BHPian Join Date: Mar 2020 Location: Blr/Kochi/Wynd
Posts: 1,486
Thanked: 7,456 Times
| |
|
| (5)
Thanks
|
|
26th August 2020, 14:34
| #36 |
| BHPian | |
|
| (1)
Thanks
|
|
26th August 2020, 15:04
| #37 |
| BHPian Join Date: May 2020 Location: New Delhi
Posts: 399
Thanked: 1,045 Times
| |
|
| (3)
Thanks
|
|
20th November 2020, 19:25
| #38 |
| BHPian Join Date: Sep 2007 Location: Bangalore
Posts: 132
Thanked: 87 Times
| |
|
|
|
8th December 2020, 17:59
| #39 |
| BHPian Join Date: Apr 2020 Location: Bangalore
Posts: 73
Thanked: 59 Times
| |
|
|
|
2nd June 2021, 13:59
| #40 |
| Newbie Join Date: Apr 2021 Location: Hyderabad
Posts: 5
Thanked: 15 Times
| |
|
| (7)
Thanks
|
|
2nd June 2021, 14:19
| #41 |
| Distinguished - BHPian  Join Date: Jun 2012 Location: BengaLuru
Posts: 5,956
Thanked: 21,234 Times
| |
|
| (4)
Thanks
|
| |
|
3rd June 2021, 11:15
| #42 |
| Senior - BHPian Join Date: Nov 2009 Location: Germany
Posts: 2,856
Thanked: 1,545 Times
| |
|
| (1)
Thanks
|
|
3rd June 2021, 11:52
| #43 |
| Newbie Join Date: Apr 2021 Location: Hyderabad
Posts: 5
Thanked: 15 Times
| |
|
| (2)
Thanks
|

|
3rd June 2021, 12:29
| #44 |
| Senior - BHPian Join Date: Nov 2009 Location: Germany
Posts: 2,856
Thanked: 1,545 Times
| |
|
| (1)
Thanks
|
|
3rd June 2021, 15:51
| #45 |
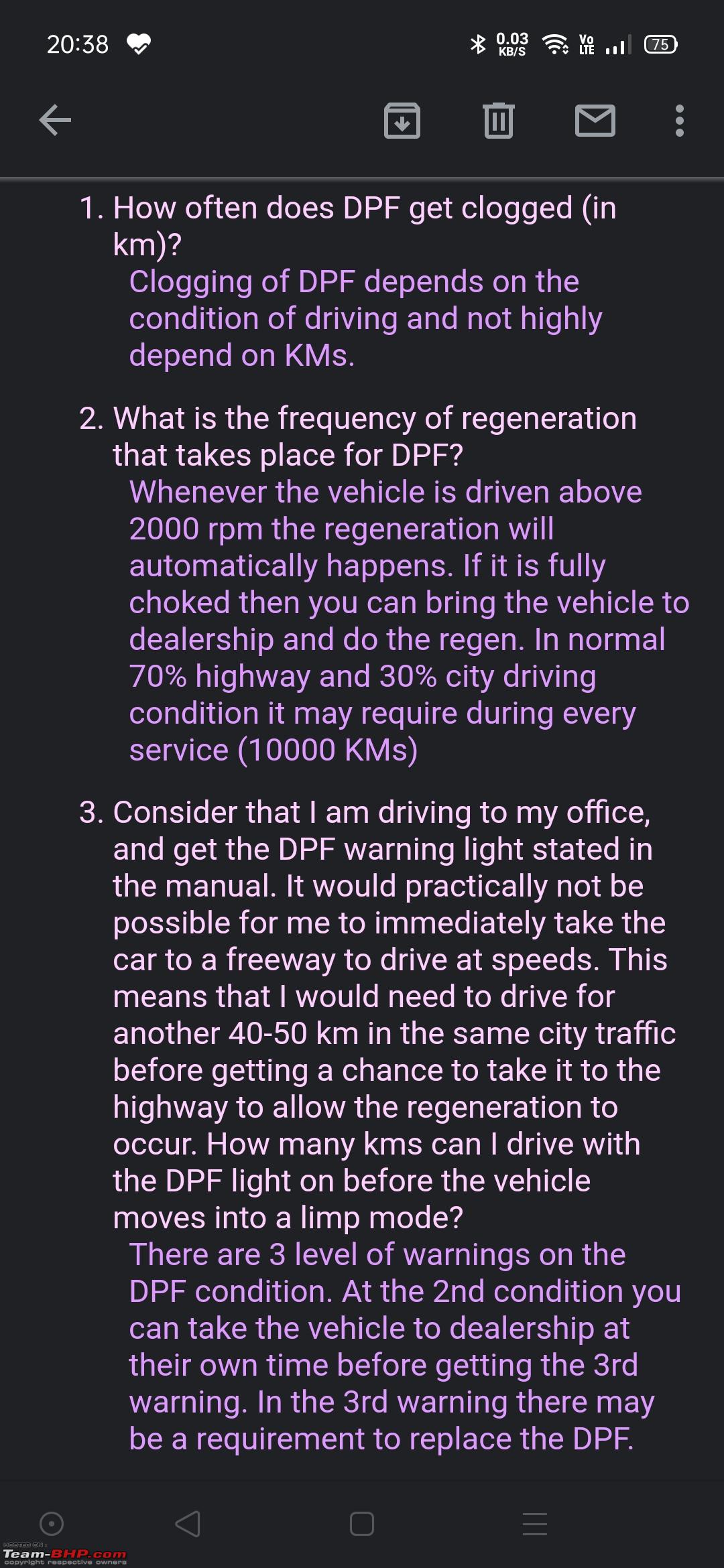
| Newbie Join Date: Apr 2021 Location: Hyderabad
Posts: 5
Thanked: 15 Times
| |
|
|
 |
Most Viewed